Building Blocks for Foundation Model Training and Inference on AWS
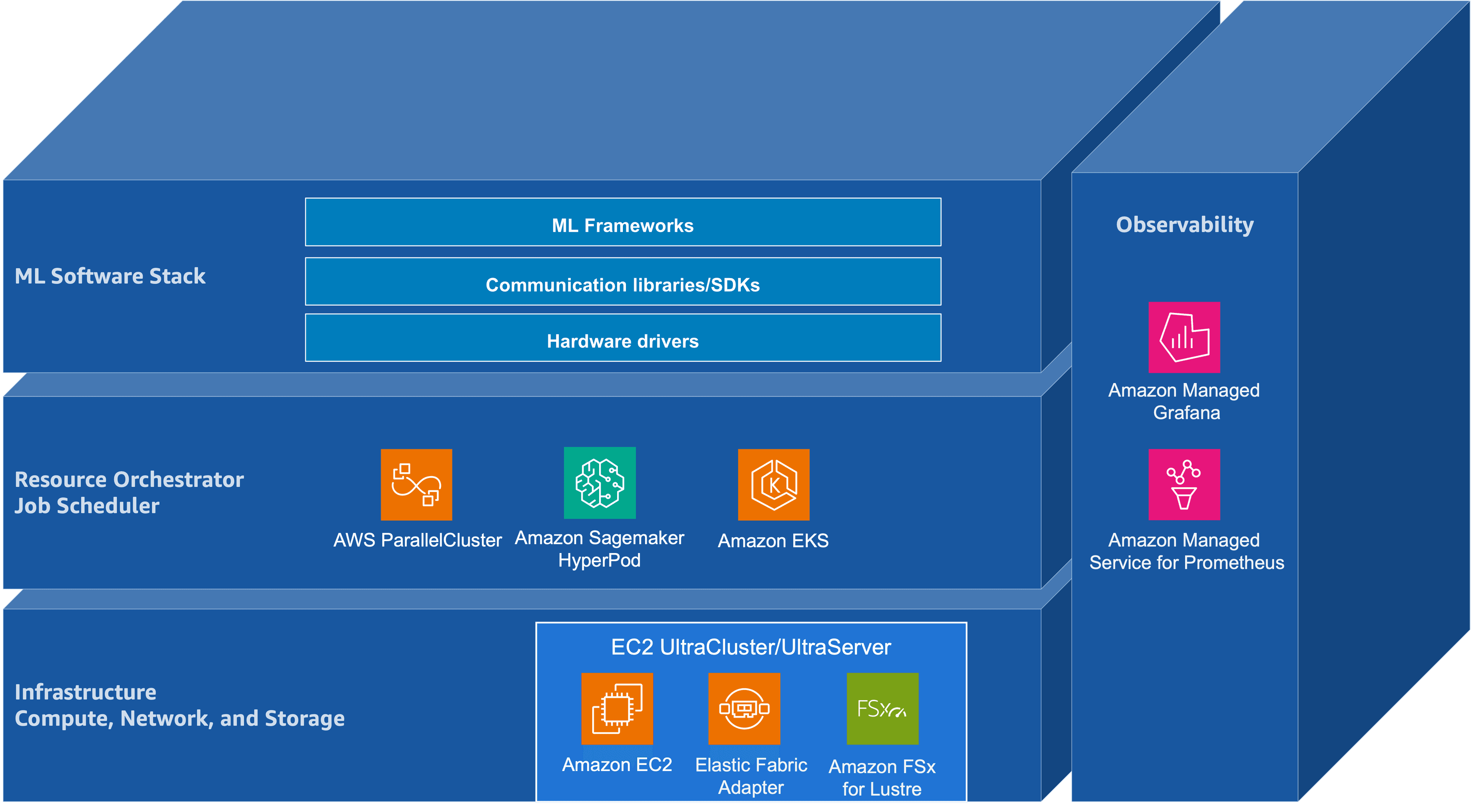
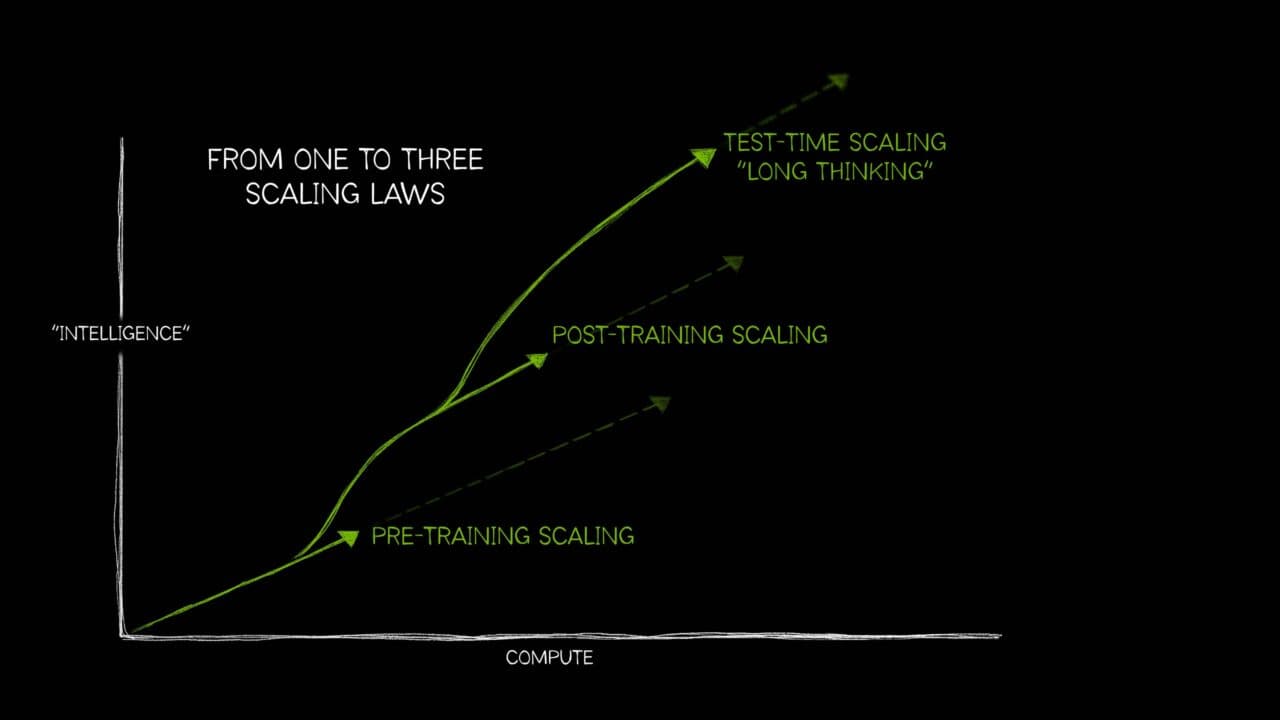
Building Blocks for Foundation Model Training and Inference on AWS Figure: Adapted from "AI's Three Scaling Laws, Explained" (NVIDIA Blog). Taken together, these scaling regimes push the foundation-model lifecycle—pre-training, post-training, and inference—toward convergent infrastructure requirements: tightly coupled accelerator compute, a high-bandwidth low-latency network, and a distributed storage backend. They also raise the importance of orchestration for resource management, and of application- and hardware-level observability to maintain cluster health and diagnose performance pathologies at scale. Another key trend is the increasing reliance of the foundation-model lifecycle on an open-source software (OSS) ecosystem that spans model development frameworks, cluster resource management, and operational tooling. At the cluster layer, resource management is typically provided by systems such as Slurm and Kubernetes. Model development and distributed training are commonly implemented in frameworks such as PyTorch and JAX. Monitoring and visualization—that is, observability—are often achieved using Prometheus for metrics collection and Grafana for visualization and alerting, positioned as an operational layer atop infrastructure and resource management. Figure 1 illustrates this layered architecture, showing how hardware infrastructure supports resource orchestration, which in turn enables ML frameworks, with observability spanning across all layers. Figure 1: The layered architecture of open-source software stacks for foundation model training and inference This post is intended for machine learning engineers and researchers involved in foundation model training and inference, with particular attention to workflows built atop OSS frameworks. It analyzes how AWS infrastructure—including multi-node accelerator compute, high-bandwidth low-latency networking, distributed shared storage, and associated managed services—interacts with common OSS stacks across the foundation model lifecycle. The primary goal is to provide a technical foundation for understanding systems bottlenecks and scaling characteristics spanning pre-training, post-training, and inference. This introductory post surfaces the overall system architecture, emphasizing the integration points between AWS infrastructure components and OSS tools that underpin large-scale distributed training and inference. The AWS Building Blocks The remainder of this series examines how this layered architecture is realized on AWS, progressing through infrastructure, resource orchestration, the ML software stack, and observability. The following sections preview each layer. Infrastructure: Compute, Network, and Storage As illustrated in Figure 1, infrastructure is anchored by three coupled building blocks—accelerated compute with large device memory, wide-bandwidth interconnect for collective communication, and scalable distributed storage for data and checkpoints. Accelerated compute forms the foundation of large-scale foundation model pre-training, post-training, and inference. AWS offers several generations of NVIDIA GPUs as part of its Amazon EC2 accelerated computing instances, including the Amazon EC2 P instance family. The P5 instance family includes p5.48xlarge with eight NVIDIA H100 GPUs, p5.4xlarge with a single H100 GPU for smaller-scale workloads, and p5e.48xlarge/p5en.48xlarge variants with NVIDIA H200 GPUs. The P6 instance family introduces NVIDIA Blackwell B200 architecture with p6-b200.48xlarge and Blackwell Ultra B300 with p6-b300.48xlarge. Across these generations, the dominant scaling axes are peak Tensor throughput, HBM capacity and bandwidth, and interconnect bandwidth (within and across nodes). As a first-order approximation, peak Tensor Core throughput—measured in floating point operations per second (FLOPS)—helps situate these accelerators on a common axis. The table below summarizes…