In-Kernel Broadcast Optimization: Co-Designing Kernels for RecSys Inference
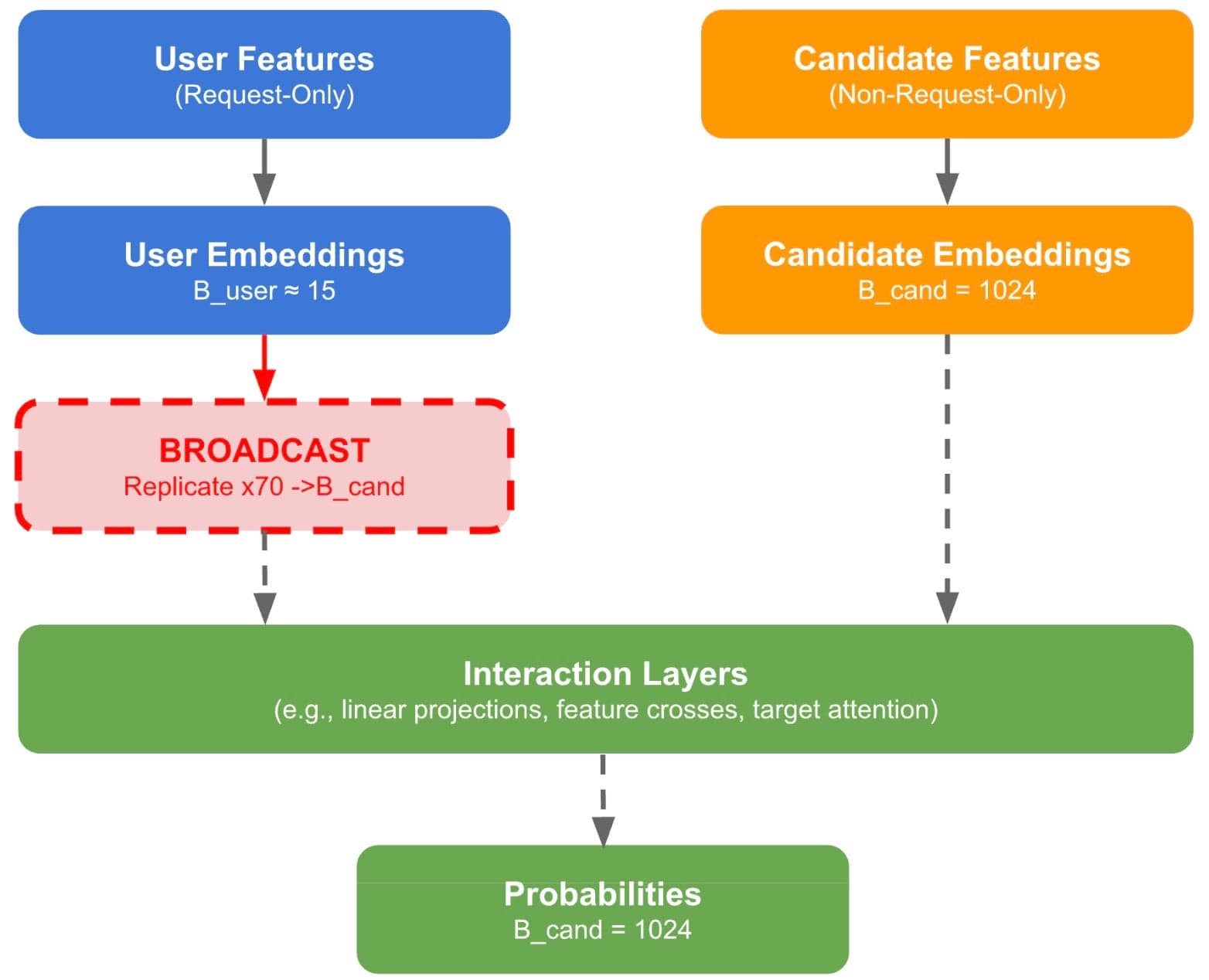
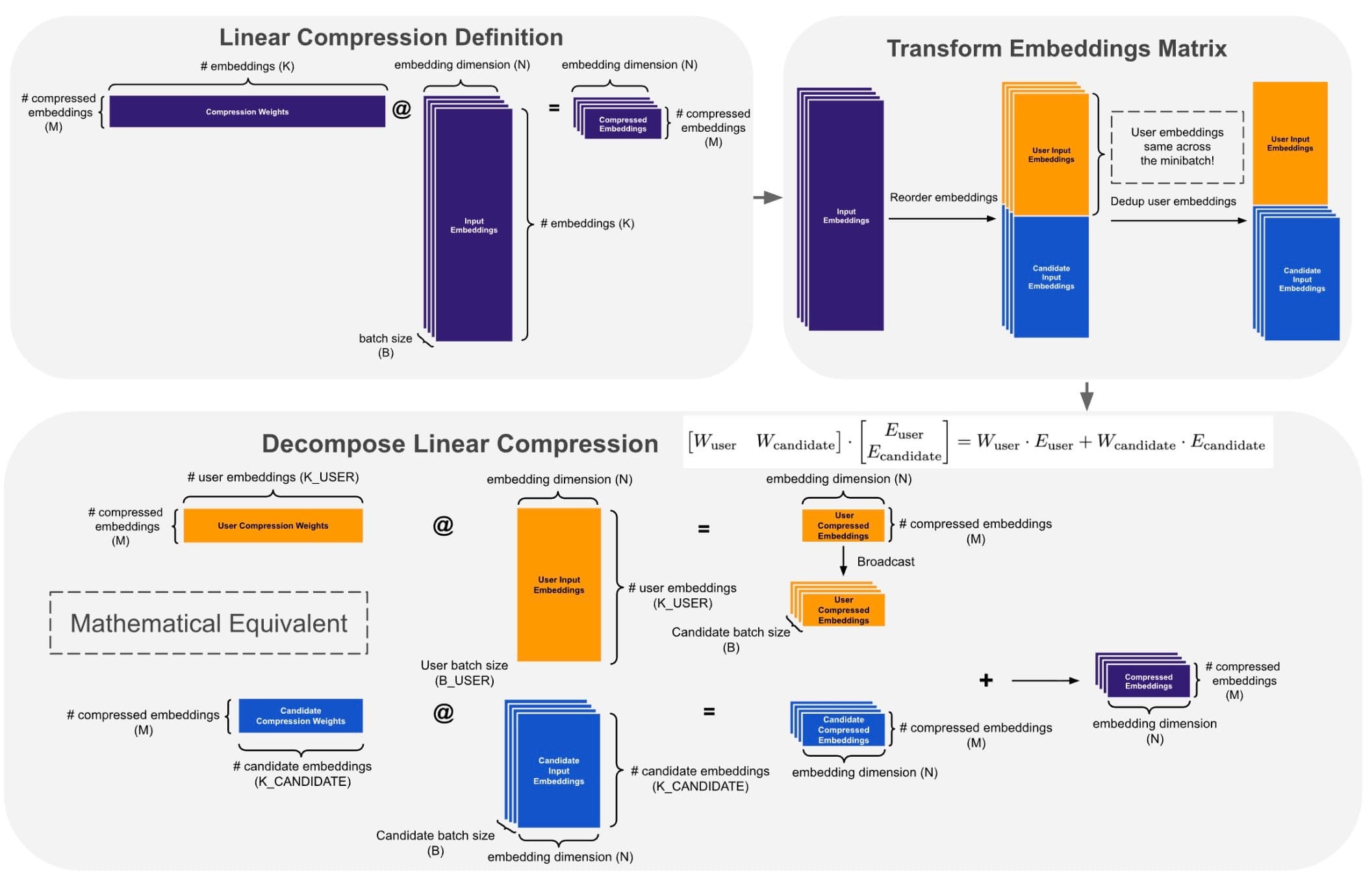
Featured projects TL;DR: - Traditional RecSys inference explicitly replicates shared user embeddings/sequences for every candidate. In-Kernel Broadcast Optimization (IKBO) eliminates this overhead via a kernel-model-system co-design that fuses broadcast logic directly into user-candidate interaction kernels. By decreasing both the memory footprint and IO utilization, IKBO unlocks even higher throughput. - IKBO delivers up to a 2/3 reduction in compute-intensive net latency, serving as the scalability backbone for the request-centric, inference-efficient framework that powers the Meta Adaptive Ranking Model. - Deployed end-to-end across Meta’s multi-stage recommendation funnel on both GPU and MTIA (Meta Training and Inference Accelerator). - The IKBO Linear Compression kernel achieved a cumulative ~4× speedup on H100 SXM5 after four stages of progressive co-design, culminating in warp-specialized fusion via TLX. - The IKBO co-design shifted the Flash Attention kernel from IO-bound to compute-bound (hitting 621 BF16 TFLOPs on H100 SXM5). Coupled with TLX warp-specialized optimization, this results in a 2.4x/6.4× throughput gain over the non-co-designed CuTeDSL FA4 Hopper baseline (kernel only/kernel + broadcasting). In this post, we present In-Kernel Broadcast Optimization (IKBO), a kernel-model-system co-design approach that eliminates redundant user-embedding broadcast in recommendation model inference. In production RecSys, user embeddings are identical across all candidates for a given request, yet standard approaches require explicit replication, wasting memory bandwidth and compute that scale with candidate count. IKBO encodes a simple insight: broadcast is a data layout concern, not a computational necessity. Each IKBO kernel accepts user and candidate inputs at their natural, mismatched batch sizes and handles broadcast internally, so no replicated tensors ever materialize. We showcase the methodology through two kernel deep dives: Linear Compression and Flash Attention. Deployed across Meta’s RecSys inference stack—from early-stage to late-stage ranking models, spanning both GPU and MTIA (Meta Training and Inference Accelerator)—IKBO delivers up to a 2/3 reduction in compute-intensive net latency on co-designed models. It serves as the scalability backbone for the request-centric, inference-efficient framework underlying the Meta Adaptive Ranking Model (serving LLM-scale models in production). On H100 SXM5, our IKBO Linear Compression kernel achieves ~4× speedup through four progressive co-design stages: matmul decomposition, memory alignment, broadcast fusion, and warp-specialized multi-stage fusion via TLX (Triton Low-Level Extensions). For Flash Attention, IKBO delivers a 2.4×/6.4× throughput compared to non-co-designed CuTeDSL FA4-Hopper (kernel only / kernel + broadcasting) with 621 BF16 TFLOPs. Unlike system-level broadcast or net-splitting that work around replication, IKBO eliminates it at the computational primitive layer, achieving dense interaction quality at near-independent cost. Code Repository: https://github.com/pytorch/FBGEMM/tree/main/fbgemm_gpu/experimental/ikbo † Work done while at Meta 1. In-Kernel Broadcast Optimization: Eliminating Memory and Compute Redundancy When a user opens their feed, the recommendation system must score hundreds to thousands of candidate items to decide what to show. The model’s inputs split into two categories: user features (e.g., browsing history, profile, context) that are identical for every candidate in a request, and candidate features (e.g., item ID, category, engagement statistics) that are unique to each item. Both pass through embedding lookups and subsequent processing to produce embedding representations. At various points in the model,…